
前几天被Google I/O开发者大会刷屏,尤其是会上Google的现任CEO桑德尔·皮查伊(Sundar Pichai)公布了在AlphaGo战胜李世石的“秘密武器”就是一块晶片“TPU”(张量处理单元,Tensor Processing Unit,),它使得机器学习类深度神经网络模型在每瓦特性能性能支撑上优于传统硬件。
其实早在去年年底,Google就已开源深度学习系统TensorFlow。
|关于深度学习开源软件
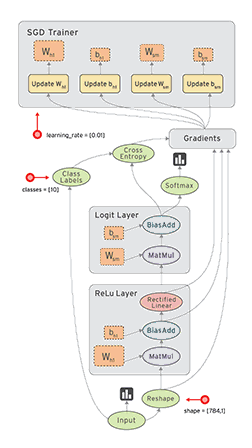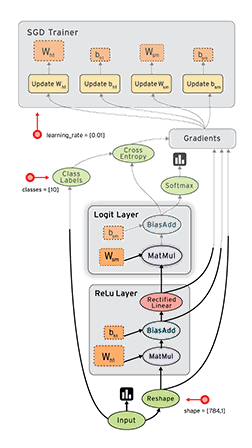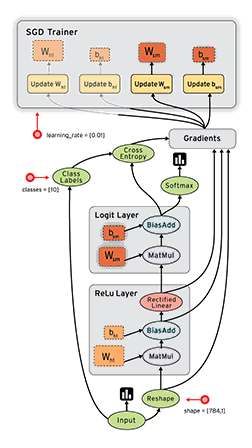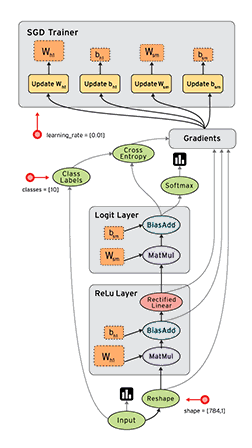
简单回顾下TensorFlow——一个开源软件库使用数据流图进行数值计算。图中的节点代表数学运算,而图形边缘表示多维数据数组(张量)之间的沟通,灵活的架构允许你计算部署到一个或多个CPU或GPU,虽然一开始谷歌大脑开发团队是主要进行机器学习的目的,和深层神经网络的研究,但总体系统足以适用于各种各样的其他领域。
这就已经使得第一代系统DistBelief大幅度被简化。因为在深度学习算法CNN流行之前,机器学习的特征学习主要是通过人类根据自身拥有的领域知识或经验来提取合适的特征,而特征的好坏直接决定了机器学习运用的成败。
但是对于图像或者语音而言,人类提取特征的标准也较难形容,譬如我们识别一朵红玫瑰,我们会觉得红玫瑰有刺、有颜色、有叶子、有花瓣和茎,而且这几个部件之间有一定组织关联以及空间约束,譬如刺在茎上的分布有一定的距离、花瓣在开放之后与尚未开放之前有一定的紧密度差距等,但是我们该用怎样的语言来描述人类“眼睛”呢?如果认真想一想就会发现挺难的。
但是人类本质上是小样本监督学习,或者无监督学习,现有的深度学习还无法做到这一点,这也是深度学习领域的研究着重需要突破的点。因为我们只要给几张开放程度不同的红玫瑰的照片给人看,他就可以学习到都些是什么样的红玫瑰。人似乎可以自动“学习”出特征,或者说你给了他看几张红玫瑰的照片,然后问红玫瑰有什么特征,他也会就可以隐约告诉你红玫瑰有什么特征,甚至是不同开放程度特有的特征,这些特征是百合花、水仙花或者其他的花没有的。
而深度学习就是人工神经网络ANN (Artificial Neural Network),是在借鉴一些人脑运行的机制基础上模拟神经元的连接设计的。因为深度学习算法相较于传统的机器学习在一些重要的任务上取得了大幅度的提升,以至于引发一场热潮甚至形容为革命也不为过,但是深度学习需要海量已标记的数据进行长时间的训练,其对计算能力的要求非常高。深度学习是计算密集型的算法,在近几年,随着计算能力的增强,深度神经网络对比许多传统机器学习数据集优势体现出来之后,逐渐用到图像、语言,它不再需要人工提取特征,自动学出特征后效果提升更明显。
最初使用传统的CPU(中央处理器,Central Processing Unit)计算时,为了保证算法的实时性,会需要使用大量的CPU来进行并行计算,就像Google Brain项目用了16000个CPU Core的并行计算平台训练来保证算法的运行速度。
深度学习是计算密集型的算法,所以在GPU (图形处理器,Graphic Processing Unit)、FPGA(现场可编程门阵列,Field-Programmable Gate Array)和TPU等超速处理硬件发展起来后,CPU 在机器学习上进行的计算量大大减少,但是CPU并不会完全被取代,因为CPU较为灵活,且擅长于单一而有深度的运算,还可以做其他事情。
比如当使用GPU做深度学习计算时,CPU还是需要在代码中写入并读取变量、执行指令、启动在GPU上的函数调用、创建小批量的数据等,但是不再需要取指、译码等,所以Google在I/O大会上也强调了其并没完全抛弃CPU,TPU 只是在一些辅助使用在特定的应用中。
|TPU对谷歌意味着什么?
谷歌专门开发的应用于深度神经网络的软件引擎。谷歌表示,按照摩尔定律的增长速度,现在的TPU的计算能力相当于未来七年才能达到的计算水平,每瓦能为机器学习提供更高的量级指令,这意味它可以用更少的晶体进行每一个操作,也就是在一秒内进行更多的操作。并且谷歌将其与Deep learning系统平台TensorFlow进行了深度绑定,可以获得更好的支持,做更强的生态,包括搜索、无人驾驶汽车、智能语音等100多个需要使用机器学习技术的项目。
TPU是什么?
TPU就是 custom ASIC specifically for machine learning ,专门为机器学习设计的专用集成电路。在Google2016 I/O上首次提及,但是并没有公布技术细节,只是在其官方博客里有披露一些信息。

ASIC并不是新鲜的东西,只不过Google利用它来做来一个定制版的ASIC,但是具体技术细节是没有披露的,而且以后会不会披露,会不会对消费者开放,这都是有待观察的,现在披露的消息是说会用在Google的云计算平台上。
遗憾的是目前并没有太多的故事可分享,唯一一个值得注意的就是Google已经使用此芯片运行了一年多的时间,而且已经用在了其大量的产品上,说明TPU已经是一个较为成熟的设计了。
到底会不会取代GPU或CPU呢?谷歌资深副总裁Urs Holzle透露,当前谷歌TPU、GPU并用,这种情况仍会维持一段时间,但也语带玄机表示,GPU过于通用,谷歌偏好专为机器学习设计的晶片。GPU可执行绘画的运算工作,用途多元,TPU属于ASIC,也就是专为特定用途设计的特殊规格逻辑IC,由于只执行单一工作,速度更快,但缺点是成本较高。
TPU并非万能
TPU的高效能的来源正是其非万能的设计逻辑(极度单一的设计原则),正如上文所说的CPU是通用计算,而GPU相对来说虽然比CPU更不通用,但是因为GPU本身是作为显卡的处理器产生的,所以GPU也是相对通用的。而TPU为专用的逻辑电路,单一工作,速度快,但由于其是ASIC,所以成本高。
另外一点有可能是TPU的暂时的缺点就是TPU现在为Google专用,还不是消费类产品,而要走向流行的消费类产品,还需要现在市场的软硬件进行配合,这也是需要一定的时间的,而且会不会得到市场最终认可也是存在疑问的。所以TPU非常不万能。
只是TPU的发布,有一点很重要的意义:现在的深度学习生态环境已经非常重视这些硬件的升级了,这些定制硬件的春天就要到来,最终这个市场鹿死谁手真是无法预料,而国内在这方面并不落后,如寒武纪,地平线这样公司也正在这方面摩拳擦掌。
虽然TPU带来了突破性进步,但这并不代表会完全淘汰CPU和GPU,目前主要会用来解决集成电路存在的成本高、耐用性差的问题。值得期待的事,Google是互联网性质的企业,在硬件制作上能否超越传统的硬件产商(如Nvidia,Intel等), 我们可以静观其变。
|目前的深度学习硬件设备还有哪些?与传统CPU有何差异?
FPGA
FPGA最初是从专用集成电路发展起来的半定制化的可编程电路,它无法像CPU一样灵活处理没有被编程过的指令,但是可以根据一个固定的模式来处理输入的数据然后输出,也就是说不同的编程数据在同一片FPGA可以产生不同的电路功能,灵活性及适应性很强,因此它可以作为一种用以实现特殊任务的可再编程芯片应用与机器学习中。

譬如百度的机器学习硬件系统就是用FPGA打造了AI专有芯片,制成了AI专有芯片版百度大脑——FPGA版百度大脑,而后逐步应用在百度产品的大规模部署中,包括语音识别、广告点击率预估模型等。在百度的深度学习应用中,FPGA相比相同性能水平的硬件系统消耗能率更低,将其安装在刀片式服务器上,可以完全由主板上的PCI Express总线供电,并且使用FPGA可以将一个计算得到的结果直接反馈到下一个,不需要临时保存在主存储器,所以存储带宽要求也在相应降低。
GPU
GPU是相对于CPU的一个概念,是一个专门的图形的核心处理器,计算机中的GPU是显卡的“心脏”,也就是相当于CPU在电脑中的作用。但是因为GPU在浮点运算、并行计算等部分的计算方面能够提供数十倍至上百倍的CPU性能,所以开始利用GPU来运行机器学习模型,以便于在云端进行分类和检测,同样的大训练集,相对于CPU耗费的时间大幅度缩短,占用的数据中心的基础设施也少很多,所以GPU在耗费功率更低、占用基础设施更少的情况下能够支持远比单纯使用CPU时10-100倍的应用吞吐量。
譬如图像识别领域的图普科技,则是基于大规模GPU集群搭建了AI超算平台,能够支持亿万级别图像的全面实时处理,并且利用深度学习算法设计的智能程序能通过快速迭代拥有强大的学习能力,实现高精度的智能识别结果。
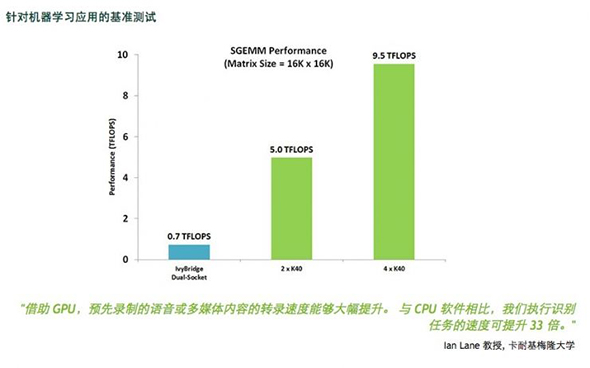
而语音识别领域的科大讯飞,目前在深度学习训练方面,几乎所有的运算包括CNN、RNN等都是放在GPU加速卡上的,并且其还计划在语音识别业务中启用FPGA平台,通过重新设计硬件架构在未来建造一个上万规模的FPGA语音识别系统。
所以可以说,要实现让机器能像人类一样思考,企业不仅需要在算法模型的精确度上下功夫,同时高性能计算能力的硬件系统也是非常需要关注的,这些异构加速技术协助处理器运算速度的快速提升,让机器学习应用领域的硬件层面难度降低。
但是现在这些只是一个开始,更多的软硬件创新肯定还在进行中,不知道是否有一天,这些创新是否也会帮助AI超越人类呢?







